Por ke la internacia lingvo plene profitu de tiu sistemo, necesas interkonsenti pri detaloj de gxia uzo.
Damit die internacia lingvo die Vorteile dieses Systems voll nutzen kann, ist eine Einigung über Einzelheiten seiner Anwendung erforderlich.
Kvankam la programado de komputiloj okazas per specialaj programadaj lingvoj, ankaux natura lingvajxo estas objekto de komputado. Plej ofte gxi aperas kiel objekto de simplaj operacioj, kiaj estas ordigo, komparo kaj substituo, aux kiel mesagxoj eligitaj de programoj; nur en specialaj cirkonstancoj gxi estas analizata laux enhavo, en traduksistemoj aux aliaj aplikoj de la "artefarita inteligenteco".
La plej multaj komputil-mastrumaj sistemoj subtenas, pro sia usona deveno, unuavice la komputadon de anglezaj tekstoj. Cxe la transiro al aliaj lingvoj aperas kelkaj malfacilajxoj, kaj pliaj cxe la komuna traktado de pluraj lingvoj.
"escepte de la angla kaj la nederlanda, preskaux cxiuj euxropaj lingvoj havas supersignojn"
kaj ecx en tiuj du lingvoj diakritaj signoj estas oportunaj por distingi inter homonimaj paroj kiaj resume/resumé kaj een/één. Tial por nova lingvo unue necesas kodo por reprezenti gxiajn literojn.
La sep-bita kodo laux la internacia normo ISO 646 (ASCII = american standard code for information interchange) posedas alilingvajn variajxojn, en kiuj kelkaj specialaj signoj estas anstatauxataj de specialaj literoj. Tiuj kodoj ebligas reprezenti tekstojn en multaj lingvoj per 7-bitaj literoj; tamen la kodo devas esti fiksa, do eblas uzi nur unu lingvon samtempe. Por lingvoj kun grandaj alfabetoj aux ideografiaj lingvoj, kia la cxina, tiu vojo ne estas irebla; same por la kuna traktado de pluraj lingvoj.
Estas eble pligrandigi la signaron de kodo per la enkonduko de t. n. eskapa simbolo (per kiu oni "eskapas" el la originala kodo). En la kodo ASCII ekzistas la negrafika simbolo ESC (numero 27) kiu plenumas diversajn, parte normigitajn, rego-funkciojn; unu el tiuj estas transiro al aliaj kodoj. Por interna vastigo de ASCII oni foje uzas la simbolon retropasxo (BS, numero 8), kiu servas por kombini la signon antaux si kun la posta. Tiu metodo plej ofte servas por diakritaj signoj, ekz-e la cirkumflekso ^ aux la citilo ", uzata kiel dierezo. La kod-vico ^-BS-c do interpreteblas kiel cx, la vico "-BS-a kiel ä.
En la kazo de egale largxaj signoj tio signifus simplan tajpadon de ambaux signoj sur la sama loko, sed eligaj aparatoj havas la plenan rajton produkti pli belan signon, ekzemple ä anstataux supermetitaj a kaj ". Tio estas necesa precipe, kie la signoj ne estas egale largxaj, cxar C kun ^ aspektas malpli bela ol Cx [se gxuste presite]. La kod-vicoj estas do konsiderendaj kiel propraj signoj, kaj la interpreto de BS kiel retro-pasxo cxi tie estas nur memorhelpo.
La uzo de negrafikaj signoj kiel eskapiloj kauxzas problemojn cxe la prezentado de tekstoj per aparatoj, kiuj konas nur la bazan kodon, ekz-e se ekran-dialogilo por la kodo ASCII estas uzata por produkti fonto-tekston por lasera printilo kun pli ampleksa signaro. Tiuokaze estas preferinde uzi grafikan simbolon kiel eskapilon, ekz-e la retro-stangon "\", kiun uzas la tekst-formatigiloj TeX kaj troff. Malavantagxo de tiu metodo estas, ke oni bezonas specialan vojon por prezenti la eskapilon mem, kiu ja estas parto de la originala kodo. Uzataj estas la duobligo de la eskapilo, aux speciala eskap-kodo, ekz-e \e (troff) aux \backslash (TeX).
Tiuj metodoj ja principe solvas la problemon de kodado de literoj ekster la baza latina alfabeto, sed ili postulas transkodadon cxe la eligo kaj faras nenaturan distingon inter la suplementa kaj la baza literaro. Ofte tiu distingo estas gxena, kaj necesas kodo kun pli granda baza signaro ol ASCII. Tial ekzistas kodoj kun pli ol sep bitoj en cxiu signo; parte ok, por ideogramoj ecx 16 bitoj.
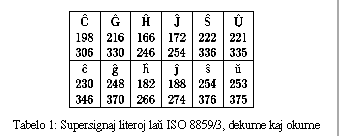
Por latinskribaj lingvoj ekzistas la internaciaj normoj ISO 6937 (plur-bajta kodo) kaj ISO 8859 (unu-bajta kodo). Ambaux kodoj uzas ok-bitan bajton por cxiu baza litero. En la plur-bajta kodo ekzistas aro de 15 diakritaj signoj, kiuj povas stari antaux aliaj literoj kaj influas ties formon; la kod-numero 195 estas por cirkumflekso kaj la kod-numero 198 por hoketo. Do, kiel Sherwood [5] atentigas, per tiu kodo eblas senriprocxa skribado de esperantezaj tekstoj: La duopo 195/67 formas "Cx", la duopo 198/117 "ux", ktp. De tiuj paroj da bajtoj, kiuj kune formas unu literon, venas la nomo "plur-bajta" kodo.
La kodo 6937 ne trovis vastan aplikon,
interalie cxar la malsama longeco de la signoj (unu aux du bajtoj)
komplikas multajn programojn,
ekz-e tekst-redaktumilojn.
Pli ofte uzata estas la kodo laux la normo ISO 8859,
kies cxiuj signoj estas unubajtaj;
literoj kaj eventualaj diakritoj formas unuon.
Pro tio ne eblas reprezenti cxiujn signojn de ISO 6937 per ok bitoj,
tiel ke necesas diversaj versioj de la kodo:
ISO 8859/1 limigas sin al la iom grandaj okcident-euxropaj lingvoj,
ISO 8859/3 enhavas ekz-e la esperantezajn literojn.
Mi prezentas iliajn kod-numerojn dekarie kaj okarie
en tabelo 1,
laux
[6,7].
Tiuj specialajxoj estas tiom malsamaj, ke necesas suficxe gxeneralaj metodoj por ordigi aux majuskligi, aux tute apartaj programoj por cxiu lingvo. Tamen estas eble utiligi ekzistantan latin-literan ordig-programon por ordigi tekstojn kun diakritaj aux specialaj literoj, se ili estas translitereblaj tiel, ke ilia komparo koincidas kun la latin-litera komparo. Post la ordigo necesas re-transliteri; do devas ne perdigxi informo. Principe tiu procedo estas ebla en cxiuj kvar menciitaj kazoj:
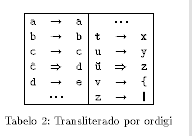
Necesas tie cxi, ke ekzistu signoj ignorataj de la ordiga programo.
La priskribitaj metodoj ne tauxgas por la kuna traktado de pluraj lingvoj. En tiu okazo oni povas nur ordigi laux la latina alfabeto, ignorante aux transliterante specialajn literojn kaj diakritajn markojn.
Por havi mesagxojn en nova lingvo necesas generi novan version de la programo el "tradukita" fonto. Se la fonto-programo ne estas disponebla, eblas "enfliki" alilingvajn tekstojn en la masxinlingvan programon, sed la novaj tekstoj ne povas esti pli longaj ol la originalaj. Nur malmultaj programoj subtenas pli facilan adapteblecon al novaj lingvoj.
Se programo enhavus cxiujn mesagxojn en pluraj lingvoj, gxia fonto-teksto farigxus malbone superrigardebla; krome la adaptado al nova lingvo estus same malfacila kiel cxe unu-lingva programo. Pli bone estas stori la mesagxojn de cxiu lingvo en po unu dosiero, de kie la programo legas ilin. Por rapide trovi iun bezonatan mesagxon, necesas tauxga organizo de la dosieroj, ekz-e kun fikse longaj rikordoj aux kun indekso al cxiuj rikordoj. Uzante la unuan metodon oni povas kompili la dosierojn per ordinara tekst-redaktumilo, sed devas precize nombri la kolumnojn; krome la fiksa longeco estas baro por la longeco de la mesagx-tekstoj. La dua metodo nepre necesigas specialajn ilojn por la produktado kaj administrado de la dosieroj.
NLS normigas la uzatajn kodojn kaj disponigas ilojn por ordigi kaj por administri mesagxarojn por program-dialogoj.
Multaj UNIX-aj programoj, inter ili la C-kompilumilo, permesas prezenti signojn per ilia okaria kodnumero, post retro-stango (\), ekz-e \101 anstataux A. Tio eblas ankaux por la specialaj signoj, tiel uzeblaj, ecx se ne en la uzata klavaro. Tiu formo estas pli bone portebla inter masxinoj.
| #include <nl_types.h> | /* bazaj deklaroj por NLS */ |
| #define NE_TROVAS 17 | /* nomo por la mesagxo */ |
| nl_catd dmkat; | /* variablo por katalogo */ |
| ... | |
| nl_init(getenv("LANG")); | /* fiksu la lingvon */ |
| dmkat= catopen("dosier_mesaghoj", 0); | /* malfermu la katalogon */ |
| ... | |
| printf(catgets(dmkat, 1, NE_TROVAS, ""), nomo); | |
| /* ... kaj, kiam bezono, skribu la mesagxon */ |
Ekzempla programo en la lingvo C estas en figuro 1. La programo unue trovas la uzendan lingvon (getenv) kaj faras bazajn instalojn pri gxi (nl_init). Poste gxi malfermas la katalogon "dosier_mesaghoj". En okazo de bezono gxi skribas el tiu katalogo la 17-an mesagxon, kiu ricevis la simbolan nomon NE_TROVAS. Ekzemplojn por diverslingvaj mesagxoj montras tabelo 3. Al "%s" estas substituata la nomo de la dosiero ne trovita.
| esperanto | "%s ne estas trovebla" |
| anglezo | "%s not found" |
| germanezo | "%s nicht gefunden" |
| italezo | "%s non trovato" |
| polezo | "niemozliwe znalezc %s" |
En la programeto de figuro 1 la numero 17 de la mesagxo ricevis simbolan nomon; tamen en la fonta versio de la katalogo la numeroj de la mesagxoj devas aperi en eksplicita formo. Ekzemplon montras figuro 2. La fonton de katalogo eblas prepari per ordinara tekst-redaktumilo; poste oni transformas gxin per la programo gencat al kompakta versio legebla por programoj.
| $set 1 |
| 1 dosiero ne skribebla |
| 2 dosiero %s estas malplena |
| 3 \346u vi volas savi la enhavon de via dosiero? |
| 4 tajpu la nomon de la dezirata dosiero |
| ... |
| 17 %s ne estas trovebla |
| ... |
Se en unu mesagxo aperas pluraj variaj (substituendaj) partoj, ilia sinsekvo povas esti malsama en diversaj lingvoj. Pro tio la eliga subprogramo nl_printf permesas indiki la sinsekvon de substituendaj parametroj per la substitu-ordonoj %1$, %2$ ktp. Figuro 3 montras ekzemplon en anglezo kaj Esperanto: La du parametroj de la mesagxo estas la nomo de iu objekto kaj gxia speco (subprogramo, biblioteko). Cxar en anglezo la nomo rolas kiel adjektivo, gxi antauxiras la specon; en Esperanto estas inverse.
| parametroj de nl_printf --> rezulto |
|---|
| The %1$s %2$s discovered an error / libint / library |
| The libint library discovered an error |
| The %1$s %2$s discovered an error / catopen / subprogram |
| The catopen subprogram discovered an error |
| La %2$s %1$s trovis eraron / libint / biblioteko |
| La biblioteko libint trovis eraron |
| La %2$s %1$s trovis eraron / catopen / subprogramo |
| La subprogramo catopen trovis eraron |
Por cxiu lingvo ekzistas la katalogo "info" kun bazaj, ofte bezonataj informoj. Ili enkludas la nomojn de monatoj kaj semajno-tagoj, la vortojn jes kaj ne, kaj la skrib-manieron de la dato kaj de nombroj (kun dekaria punkto aux komo).
Cxiu programo havu unu preferatan lingvon (sian "denaskan"), kiu estas uzata, se katalogo por la petata lingvo ne ekzistas.
La programo sort konsideras la valoron de LANG por gxuste ordigi diverslingvajn tekstojn; tamen ne estas eble ordigi diversajn kolumnojn de tabelo laux malsamaj lingvoj, ekz-e lando-nomojn laux la internacia lingvo kaj, cxe egalaj lando-nomoj, personajn nomojn sen konsidero de specialaj signoj.
Evidente la verkado de internacia programo estas iom pli peniga ol de tradicia unu-lingva programo. Tamen NLS sxajnas racia vojo al pli granda lingva komforto en la uzo de komputiloj. Gxuste por uzantoj de la internacia lingvo, kiuj ja havas pli ol mezume da internaciaj kontaktoj, tiu metodo internaciigi programojn devus esti interesa.
La mallongigo por Esperanto laux ISO 639 estas eo. (Bedauxrinde, la germana normo DIN 2335, kiu bazigxas sur ISO 639, ne transprenis tiun mallongigon.) Se estas bezono por plenvorta nomo, kredeble la nomo "esperanto" estus tauxga, cxar pli konata kaj pli preciza ol la originala nomo "internacia".
La kodo ISO 8859/3 certe proponas sin kiel la normala NLS-a kodo por Esperanto; en plurlingvaj aplikoj oni povus havi alternativan version kun la kodo 6937 (esperanto.6937).
Por la katalogo info necesas interkonsenti pri la formoj de la dato kaj de nombroj. La preferata formo de la dato en Esperanto sxajnas esti la "racia" formo laux la sinsekvo de malkreska graveco, jaro-monato-tago:
La NLS-a skemo por semajno-tago, dato, horo, minuto, sekundo kaj tempo-zono do estus, almenaux gxis la jaro 2000,
(En la jaro 1999, oni eble decidos, ke "19" en certaj kuntekstoj estas alia nomo por "20".)
Krome necesas decidi, cxu skribi frakciajn nombrojn kun dekaria komo aux punkto. PIV [9] diras:
komo (2): signo, kiun oni uzas en kelkaj landoj por apartigi la decimalojn disde la unuoj
frakcio (1): ... decimala ~o ... kutime skribata per komo
PAG [8] ecx pli klare konstatas (8, rim. II):
... la anglosaksoj uzas la punkton por apartigi la unuojn disde la decimaloj, dum la euxropanoj uzas por tio komon. Cxi lasta signadmaniero sxajnas preferinda.
Efektive decimalaj frakcioj en esperantezaj tekstoj plej ofte aperas kun komo.
Unu afero kauxzas apartajn malfacilajxojn: info volas scii la uzatan valuton -- kaj se oni ne volas indiki internaciajn respond-kuponojn, kredeble necesas lasi tiun punkton libera.