Enkonduko en la aŭtomatan daten-prilaboradon
Enkonduko en la aŭtomatan daten-prilaboradon
7 Kodado de datenaj tipoj: ne-aski-aj simboloj7.1 Modifoj de AskioLa kodo Askio enhavas nur 2×26 literojn, tiujn de la angla formo de la latina alfabeto (A–Z, a–z). Ili ne sufiĉas por aliaj lingvoj, kiuj uzas literojn kun "kromsignoj" (ekz. á, â, à, ä, ā, ă, ą) kaj proprajn liter-formojn (ekz. æ, œ, ß, ð). |
7 Kodierung von Datentypen: Nicht-ASCII-Zeichen7.1 Modifikationen von ASCIIDer ASCII-Kode umfasst nur 2×26 Buchstaben, nämlich die der englischen Variante des lateinischen Alphabets (A–Z, a–z). Sie reichen für andere Sprachen, die Buchstaben mit "Unterscheidungszeichen" (z. B. á, â, à, ä, ā, ă, ą) und besondere Buchstabenformen (z. B. æ, œ, ß, ð) benutzen, nicht aus. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Tiaj specialaj simboloj foje estas kodataj per ŝanĝo de jenaj malpli uzataj Askiaj signoj: @[\]{|}~. Tio okazis precipe en tempoj, kiam pro diversaj restriktoj oni uzis nur 7 bitojn en bajto. Nun tamen plej ofte oni uzas la bajtojn inter 160 kaj 255, eluzante ĉiujn 8 bitojn en bajto. Ĉar ili ne sufiĉas por ĉiuj lingvoj, oni difinis diversajn normojn (laŭ la nomo "ISO 8859"), precipe: |
Solche speziellen Symbole werden manchmal durch Änderung folgender nicht so oft benutzter ASCII-Zeichen kodiert: @[\]{|}~. Das geschah vor allem zu Zeiten, als man wegen verschiedener Einschränkungen nur 7 Bits in einem Byte benutzte. Jetzt verwendet man meistens die Bytes zwischen 160 und 255 und nutzt alle 8 Bits in einem Byte. Da sie trotzdem nicht für alle Sprachen ausreichen, wurden verschiedene Normen (unter der Bezeichnung ISO 8859) definiert, insbesondere: | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
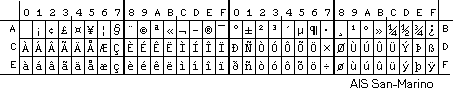
La sekva bildo montras la duan duonon de la signaro de la kodo 8859-1; la suba parto, identa al Askio, ne estas montrata: |
Das folgende Bild zeigt die zweite Hälfte des Kodes 8859-1; die erste Hälfte, die mit ASCII identisch ist, ist nicht dargestellt: | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
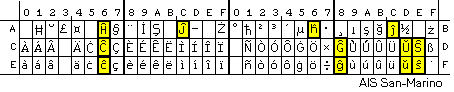
La sekva bildo montras la signaron de la kodo 8859-3; la super-signaj literoj de la Internacia Lingvo Esperanto estas flave markitaj: |
Das folgende Bild zeigt die Zeichen des Kodes 8859-3; die Esperanto-Buchstaben mit Überzeichen sind gelb markiert: | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Kelkaj literoj estas samloke kodataj en la tri kodoj 8859-1, -2, -3; ekzemple la vokaloj kun korno (á, é, ...), malkorno (à, è, ...) kaj ĉapelo (â, ê, ...) kaj la Germanaj umlaŭtoj (äöü). |
Manche Buchstaben werden in allen drei Kodes 8859-1, -2, -3 an denselben Positionen kodiert, zum Beispiel die Vokale mit Akut (á, é, ...), Gravis (à, è, ...) und Zirkumflex (â, ê, ...) und die deutschen Umlaute (äöü). | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
7.2 Kodoj en VindozoVindozo de sia komenco uzis la kodon Latina-1 (sub la nomo "ANSI-kodo") kaj ofte iom pligrandigas ĝin al la "kod-paĝo 1252" (KP 1252), kiu uzas ankaŭ la kod-poziciojn de 128 al 159, kiujn Latina-1 ne uzas. Por landoj, kies lingvoj bezonas aliajn literojn, ekzistas pliaj "kod-paĝoj". |
7.2 Kodes in WindowsWindows benutzte von Anfang an den Kode Latin 1 (unter dem Namen "ANSI-Kode") und erweitert ihn oft zur "Kode-Seite 1252" (CP 1252), die auch die Kode-Positionen von 128 bis 159 ausnützt, die in Latin-1 unbelegt sind. Für Länder, deren Sprachen andere Buchstaben benötigen, gibt es weitere "Kode-Seiten". | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
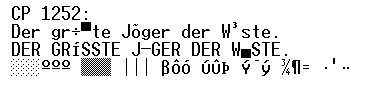
La unuaj versioj de Vindozo teknike baziĝis sur la sistemo DOS. DOS uzis alian kod-paĝon, kun numero 437. Ankaŭ KP 437 estas kongrua kun Askio, do la kodoj de 32 al 127 havas la samajn valorojn kiel en Askio. Sed la pli altaj numeroj havas tute aliajn signifojn. La vindoza "komando-interpretilo" (CMD), kiu ekzistas ankaŭ en novaj Vindozoj, funkcias kiel la iama DOS-interpretilo, kaj ĝi ankoraŭ uzas KP 437. Tial tekstoj skribitaj en Vindozo ofte aspektas strange en CMD, kaj inverse. Malgranda ekzemplo tion montras; ĝi eliras de jena teksto: |
Die ersten Versionen von Windows basierten technisch auf dem System DOS. DOS benutzte eine andere Kode-Seite, mit der Nummer 437. Auch 437 ist kompatibel mit ASCII, die Kodes 32 bis 127 haben dieselben Werte wie in ASCII. Höhere Nummern haben allerdings ganz andere Bedeutungen. Der Windows-Kommando-Interpretierer (CMD), der auch in den neueren Windows-Versionen existiert, funktioniert wie der frühere DOS-Interpretierer und verwendet noch die Kode-Seite 437. Daher sehen in Windows geschriebene Texte unter DOS oft seltsam aus, und ebenso umgekehrt. Ein kleines Beispiel zeigt das ausgehend von dem folgenden Text: | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Se oni kodas tiun tekston en KP 1252 (Vindozo) kaj montras en KP 437 (DOS), la rezulto estas jena (la aski-aj signoj restas sen-ŝanĝaj): |
Wenn man diesen Text in CP 1252 (Windows) kodiert und in CP 437 (DOS) anzeigt, ergibt sich Folgendes (die ASCII-Zeichen sind unverändert): | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Se, inverse, oni kodas tiun tekston en KP 437 (DOS) kaj montras en KP 1252 (Vindozo), la rezulto estas jena (la samaj literoj estas modifitaj, sed en alia maniero): |
Kodiert man umgekehrt den Text in CP 437 (DOS) und zeigt ihn in CP 1252 (Windows) an, so ergibt sich Folgendes (dieselben Buchstaben sind verändert, jedoch auf andere Art): | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Jen la kod-valoroj de la unua linio de tiu ĉi teksto: |
Hier die Kode-Werte der ersten Zeile dieses Textes: | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
7.3 Unikodo |
7.3 Unicode | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
En 1991 aperis nova kodosistemo kun la nomo Unikodo (UNICODE). Tiu sistemo komence kodis ĉiun signon per 16-bita nombro kaj tiel teorie povis kodi 216 = 65.536 signojn. Tiel ĝi povas kodi ne nur por la specialaj signoj de ĉiuj latinskribaj lingvoj, sed ankaŭ por aliaj skriboj, inkluzive de la ĉina kaj de la japana. Unikodo estas la interna kodo uzata en la programad-lingvo JAVA kaj en la dosiera sistemo de novaj Vindozoj (ek de Vindozo NT). |
1991 erschien ein neues Kodesystem mit dem Namen Unicode [junikoud]. Dieses System kodierte jedes Zeichen mit einer 16-Bit-Nummer und konnte theoretisch 216 = 65.536 Zeichen kodieren. Daher konnte es nicht nur alle besonderen Zeichen der lateinisch geschriebenen Sprachen kodieren, sondern auch andere Schriften, einschließlich des Chinesischen und des Japanischen. Unicode wird als interner Kode der Programmiersprache JAVA und des Dateisystems der neueren Windows-Systeme (seit Windows NT) verwendet. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Kvankam la salto de 8-bitaj kodoj al 65.536 signoj estis grandega, montriĝis, ke eĉ tiom da signoj ne sufiĉas. Unikodo nun uzas iom pli ol unu milionon "kod-punktojn" (= numeroj); tute precize estas 1.114.112 kod-punktoj (17 × 216). Ĝis nun Unikodo difinis signojn por ĉ. 100.000 kodpunktoj; restas do konsiderinda "rezervo".
Eĉ kiam Unikodo estos plejparte anstataŭinta la aliajn kodojn,
la kodado de signoj devos plu evolui, ĉar ekestadas novaj signoj.
Ekzemple en Eŭropo graviĝis la eŭro-simbolo
( Tamen estas principo, ke unikoda signo neniam estu modifita aŭ forigita el la kodo. |
Obwohl der Sprung von einem 8-Bit-Kode zu 65.536 Zeichen gigantisch war, stellte es sich heraus, dass sogar diese Menge an Zeichen nicht ausreicht. Unicode umfasst jetzt (2005) etwas mehr als eine Million "Kode-Punkte" (= Nummern); ganz genau sind es 1.114.112 Kode-Punkte (17 × 216). Bis jetzt (2005) hat Unikode erst etwa Zeichen für 100.000 Kode-Punkte definiert; es verbleibt also noch eine beträchtliche Reserve.
Auch wenn Unicode einmal alle anderen Kodes weitgehend ersetzt haben wird,
muss sich die Zeichenkodierung weiter entwickeln,
denn ständig entstehen neue Zeichen.
Zum Beispiel hat in Europa das Euro-Zeichen
( Es gilt aber der Grundsatz, dass ein Unicode-Zeichen niemals verändert oder aus dem Kode entfernt werden darf. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Specimenaj demandoj |
Beispielfragen |
|
|