4 Teknikaj problemoj de plurlingveco
4 Technische Probleme der Mehrsprachigkeit
La metodoj, traduki tekstojn en la maŝina aŭ fonta program-kodo, estis multe aplikataj, sed ili havas elementajn malavantaĝojn.
4.1 Malsama longeco de tekstoj
Samsignifaj tekstoj kutime havas malsaman longecon en diversaj lingvoj. Ni vidis en la supra ekzemplo, ke la germana teksto "Division durch Null" havis 19 signojn, sed la teksto en Esperanto, "divido per nulo", nur 15. Tio povas kaŭzi problemon ĉe la tradukado en maŝinkoda programo, ĉar tie ne eblas plilongigi tekstojn. Se la tradukita teksto estas pli longa ol la originala, necesas iel mallongigi ĝin.
Ĉe tradukado en fonto-kodo tiu problemo ne aperas, ĉar alt-nivelaj aŭ asemblaj programad-lingvoj adaptas programon al la longo de uzataj tekstoj. Nur kelkfoje okazas, ke la longo de la teksto aperas ankaŭ en la program-kodo. Tiam necesas adapti ankaŭ ĝin.
Jen ekzemplo, kiun oni nuntempe ne tiel programus: El unu mesaĝo-teksto oni produktas du mesaĝojn ("divido per nulo en linio 137", "divido per nulo"). Tiaj teknikoj, nun konsiderataj kiel "malpuraj" kaj evitindaj, estis kutimaj, kiam komputiloj estis malgrandaj kaj memoro multekosta. La ekzemplo tranĉas la germanan tekston post 19 signoj, sed la Esperanto-tekston post 15:
Obwohl die Verfahren, Texte im Maschinen- oder Quell-Kode zu übersetzen, vielfach angewandt wurden, haben sie grundlegende Nachteile.
4.1 Unterschiedliche Textlänge
Texte mit gleicher Bedeutung haben in verschiedenen Sprachen unterschiedliche Länge. Wir haben in unserem Beispiel gesehen, dass der deutsche Text "Division durch Null" 19 Zeichen hat, der Esperanto-Text "divido per nulo" dagegen nur 15. Das kann zu Problemen bei der Übersetzung im Maschinenkode führen, weil man dort Texte nicht verlängern kann. Wenn der übersetzte Text länger als das Original ist, muss man abkürzen.
Bei der Übersetzung im Quell-Kode tritt dieses Problem nicht oder kaum auf, weil höhere Programmiersprachen und Assemblersprachen ein Programm automatisch an die Länge der benutzten Texte anpassen. Gelegentlich kommt allerdings auch die Länge eines Textes im Programm vor. Dann muss auch sie angepasst werden.
Hier ein Beispiel, das man heute in Java nicht mehr so programmieren würde: Aus demselben Text sollen zwei Meldungen ("Division durch Null in Zeile 137", "Division durch Null") erzeugt werden. Solche Techniken, die heute als unsauber gelten, waren durchaus üblich, als die Rechner noch klein waren und Speicher noch teuer war. In dem Beispiel wird der deutsche Text nach 19 Zeichen abgeschnitten, der Esperanto-Text aber nach 15:
String mesagxo = "Division durch Null in Zeile ";
...
System.err.println(mesagxo + " 137");
...
System.err.println(mesagxo.substring(0, 19);
|
| estas tradukita al / wird übersetzt zu |
String mesagxo = "divido per nulo en linio ";
...
System.err.println(mesagxo + " 137");
...
System.err.println(mesagxo.substring(0, 15);
|
4.2 Organizado de ŝanĝoj en programoj
4.2.1 La problemo
Grava problemo por plurlingveco estas, ke programoj ne estas konstantaj objektoj. Programoj evoluas, ili estas plibonigataj, akiras novajn kapablojn; ekestas novaj versioj de programoj.
Tradukadon de tekstoj en maŝin-kodo necesas komplete refari por ĉiu nova versio de la programo. Eĉ se nova versio uzas la samajn tekstojn kiel la antaŭa, aŭ nur kelkaj aldoniĝis, necesas komplete refari la anstataŭigon de la tekstoj. Pro tio oni ofte emas ne transiri al nova versio por ŝpari la novan tradukadon.
Se oni modifas la fonto-kodon, ekzistas du ebloj:
- Oni faras la modifojn en unu lingvo kaj poste anstataŭigas la tekstojn por traduki. Tiu procedo estas komplete analoga al la modifado de maŝin-kodo, kaj ĝi estas same nekontentiga.
- Oni faras la modifojn en ĉiuj jam ekzistantaj lingvaj variantoj. Tio estas teda, neinteresa laboro, kaj estas granda risko, ke enŝteliĝas eraroj.
4.2.2 La solvo: teksto-listoj
La solvo por tiu problemo estas klara: Necesas disigi la funkciadan parton de la programo (la "logikon") disde la tekstoj. Tiam ekzistas nur unu varianto de la program-kodo kaj aparte pluraj teksto-listoj por pluraj lingvoj. La tekstoj estas identigataj per numeroj aŭ per nomoj, kiuj povas esti en la lingvo de la programisto(j), ĉar la uzuloj ne vidos la nomojn.
Kiam okazas ŝanĝoj en la programo, oni procedas jene:
- La ŝanĝoj estas farataj al la (sola) program-fonto; ĝi ne enhavas tekstojn, sed nur numerojn aŭ teksto-nomojn.
- Kiam necesas nova teksto, programisto elektas novan numeron aŭ nomon, uzas ĝin en la programo kaj enmetas ĝin en unu (fiksitan) teksto-liston.
- Tradukistoj tradukas la novajn tekstojn kaj kompletigas la alilingvajn tekstolistojn.
- Kiam la ruliĝanta programo bezonas tekston, ĝi prenas ĝin el la teksto-listo por la lingvo, kiun la uzulo elektis.
Kondiĉo por la uzo de teksto-listoj estas, ke la programo ne enhavas fiksajn tekstojn, sed prenas ĉiujn tekstojn el listo(j). Tio estas grava parto de la internaciigo. Ĝi estas ebla nur sur la nivelo de la fonto-kodo; la maŝina kodo preskaŭ ne ebligas internaciigon.
La principo de la teksto-listoj jam estis realigita de HP-NLS en 1985. HP-NLS nomis la teksto listojn per la angla vorto "catalog", do proksimume "katalogo". La transformo de teksta numero aŭ nomo al teksto el listo estas tipa tasko por internaciiga kadraĵo.
4.2 Organisation von Programm-Änderungen
4.2.1 Das Problem
Ein wichtiges Problem der Mehrsprachigkeit ist es, dass Programme keine unveränderlichen Objekte sind. Programme entwickeln sich, erwerben neue Fähigkeiten; es entstehen neuen Versionen von Programmen.
Eine Übersetzung von Texten im Maschinen-Kode muss für jede Programmversion vollständig neu gemacht werden. Auch wenn die neue Version dieselben Texte verwendet wie die vorige oder nur einige Texte hinzufügt, muss das Ersetzen der Texte wiederholt werden. Daher bleibt man in solchen Fällen oft lieber bei der alten Version, um die neue Übersetzung zu sparen.
Wenn man den Quell-Kode modifiziert, gibt es zwei Möglichkeiten:
- Die Modifikationen werden in einer Sprache durchgeführt, anschließend werden die Texte wieder durch die Übersetzungen ersetzt. Das ist analog zur Modifikation des Maschinen-Kodes und ebenso unbefriedigend.
- Die Modifikationen werden in allen existierenden Sprachen parallel durchgeführt. Das ist eine langweilige, uninteressante Arbeit, und die Gefahr ist groß, dass sich Fehler einschleichen.
4.2.2 Die Lösung: Textlisten
Die Lösung für dieses Problem ist klar: Man muss die funktionellen Teile des Programms (die "Logik") von den Texten trennen. Dan gibt es nur eine Variante des Programm-Kodes (Quell-Kode) und getrennt davon mehrere Textlisten für verschiedene Sprachen. Die Texte werden durch Nummern oder Namen identifiziert, wobei die Namen aus der Sprache der Programmierer kommen können, denn der Benutzer wird diese Namen nicht sehen.
Wenn es eine Programmänderung gibt, wird folgendermaßen vorgegangen:
- Die Änderungen werden in der (einzigen) Programmquelle gemacht; sie enthält keine Texte, sondern nur Nummern oder Text-Namen.
- Wenn ein neuer Text erforderlich ist, wählt der Programmierer eine neue Nummer oder einen neuen Namen, verwendet ihn im Programm und fügt ihn in eine bestimmte Textliste ein.
- Übersetzer übersetzen die neuen Texte und vervollständigen somit die Textlisten der anderen Sprachen.
- Wenn das ablaufende Programm einen Text braucht, nimmt es ihn aus der Textliste für die Sprache, die der Benutzer gewählt hat.
Voraussetzung für die Verwendung von Textlisten ist, dass das Programm keine festen Texte enthält, sondern alle Texte aus (einer) Liste(n) entnimmt. Das ist ein wichtiger Teil der Internationalisierung. Sie ist nur auf der Ebene des Quell-Kodes möglich; der Maschinenkode erlaubt fast keine Internationalisierung.
Das Prinzip der Textlisten wurde bereits 1985 in HP-NLS realisiert. Dort hießen die Textlisten auf Englisch "catalog", also etwa "Katalog". Die Umsetzung von Textnummern oder Textnamen in Texte aus einer Liste ist eine typische Aufgabe für einen Internationalisierungs-Rahmen.
4.3 Malsamaj signaroj, alfabetoj kaj skribsistemoj
4.3.1 La problemo
Komence de la 1980-aj jaroj la plej multaj komputiloj estis konstruataj en Usono kaj Japanio, kaj preskaŭ ĉiuj mastrumaj sistemoj venis el Usono. Tio kaŭzis, ke la uzataj signo-kodoj orientiĝis laŭ la angla lingvo, kiu uzas preskaŭ nur la bazan latinan alfabeton sen diakritaj signoj. Estas kelkaj, malmultaj anglaj vortoj kun diakritaj signoj (ekz. resumé, por distingi ĝin de resume), sed tiujn oni ignoris. Necesis do signo-kodo, kiu enhavas
- 26 minusklajn latinajn literojn
- 26 majusklajn latinajn literojn
- 10 eŭropajn-arabajn ciferojn
- spaceton
- ĉirkaŭ 20 interpunkciojn: !?"$%&/()[]<>+-*=,.;:
- kelkajn reg-signojn, ekzemple "nova linio", "nova paĝo", "fino de datenoj"
La komputila aparataro pli kaj pli baziĝis sur grupoj de ok bitoj (nomataj bitokoj aŭ bajtoj). Ĉar la supre menciitaj signoj estas facile kodeblaj per 7 bitoj, oni normigis 7-bitan kodon nomatan ASCII (angle American Standard Code for Information Interchange = Usona Norma Kodo por Inform-Interŝanĝo); en Esperanto ĝi nomiĝas "Askio".
La ne-latin-skribaj kaj la plej multaj latin-skribaj lingvoj ne estas prezenteblaj per Askio:
- Multaj lingvoj uzas alian alfabeton ol la latinan, ekzemple la grekan (αβγ...), la cirilan (абв...), la tajan (กขฃ...) ktp.
- Kelkaj lingvoj ne uzas alfabeton, sed grandan aron da ideogramoj (ĉina, japana, ...).
- Multaj latinskribaj lingvoj uzas diakritajn signojn, ekzemple áâàåäãø...
- Multaj latinskribaj lingvoj uzas ligaturojn kaj aliajn specialajn literojn, ekzemple ÆŒßÐÞ
- Kelkaj lingvoj havas specialajn simbolojn por la valuto (¥), kelkaj ankaŭ por interpunkcioj, ekzemple la hispana (¡¿).
4.3 Unterschiedliche Zeichensätze, Alphabete und Schriftsysteme
4.3.1 Das Problem
Anfang der 1980-er Jahre wurden die meisten Rechner in den USA und Japan hergestellt, und fast alle Betriebssysteme kamen aus den USA. Daher orientierten sich die verwendeten Zeichen-Kodes an der englischen Sprache, die fast nur das lateinische Grundalphabet ohne diakritische Zeichen benutzt. Es gibt einige, wenige englische Wörter mit diakritischen Zeichen (z. B. resumé, zur Unterscheidung von resume), die man aber ignorierte. Man brauchte nur einen Zeichen-Kode, der folgendes enthält:
- 26 lateinische Kleinbuchstaben
- 26 lateinische Großbuchstaben
- 10 europäisch-arabische Ziffern
- das Leerzeichen
- etwa 20 Satz- und Sonderzeichen: !?"$%&/()[]<>+-*=,.;:
- einige Steuerzeichen, zum Beispiel "neue Zeile", "neue Seite", "Datenende"
Die Rechner konzentrierten sich von der Geräteseite (hardware) immer mehr auf Gruppen von 8 Bits (genannt Oktette oder Bytes). Da die aufgeführten Zeichen sich leicht mit 7 Bits kodieren lassen, wurde ein 7-Bit-Kode mit dem Namen ASCII (engl. American Standard Code for Information Interchange = amerikanischer Standard-Kode für Informationsaustausch) normiert.
Sprachen, die nicht die lateinische Schrift verwenden, und auch die meisten Sprachen mit lateinischer Schrift sind mit ASCII nicht darstellbar:
- Viele Sprachen verwenden ein anderes Alphabet als das lateinische, zum Beispiel das griechische (αβγ…), das kyrillische (абв...), das thailändische (กขฃ...) usw.
- Manche Sprachen verwenden kein Alphabet, sondern eine große Menge von Ideogrammen (Chinesisch, Japanisch, ...).
- Viele Sprachen mit lateinischer Schrift verwenden diakritische Zeichen, zum Beispiel áâàåäãø...
- Viele Sprachen mit lateinischer Schrift verwenden Ligaturen und andere Sonderbuchstaben, zum Beispiel ÆŒßÐÞ
- Einige Sprachen haben besondere Zeichen für Währungen (¥) oder für die Interpunktion, zum Beispiel Spanisch (¡¿).
4.3.2 Simplaj solvoj
Facila, sed ne vere kontentiga solvo de tiu problemo estis uzi anstataŭajn sistemojn, kiuj bezonas nur la askiajn signojn. Tiaj sistemoj parte jam ekzistis pro la neceso sendi internaciajn telegramojn en tiuj lingvoj. Ekzemple:
- Kelkaj lingvoj havas establitan anstataŭan sistemon, kiu uzas
nur la bazajn anglajn-latinajn literojn. Ekzemple la germana lingvo
povas skribi la du-punktajn "umlaŭtojn" per aldonita litero "e":
"ä"
 "ae",
"ö""oe",
"ü""ue".
"ae",
"ö""oe",
"ü""ue".
- Kelkaj lingvoj anstataŭigas diakritajn markojn per postmeto de
iuj signoj. Ekzemple la itala lingvo povas uzi apostrofon anstataŭ
kornon super vokalo:
"à""a`"
ktp.
- Kelkaj lingvoj povas simple forlasi la diakritajn markojn; tio faciligas la skribadon, sed malfaciligas la legadon.
Lingvoj kun ne-latina alfabeto aŭ kun ne-alfabeta skribo ne povas uzi Askion, escepte se oni transliterumas.
4.3.3 Surmetado de pluraj signoj
Diakritaj signoj aspektas proksimume, kvazaŭ oni prenis bazan latinan literon kaj sur- aŭ submetis ion.
Tial oni proponis reprezenti diakritajn signojn per du signoj presitaj en la sama loko.
Por atingi tion oni intermetis retro-paŝon, la signon,
kiun en skribmaŝina klavaro ofte simbolas sago al maldekstro
(![]() ).
Jen kelkaj ekzemploj:
).
Jen kelkaj ekzemploj:
| á | ' | apostrofo anstataŭ korno |
| ä | " | citilo anstataŭ tremao |
| ç | , | komo anstataŭ cedilo |
Se oni sur papero kunmetas la signojn laŭ tiu maniero, ili ne aspektas tre bele; sur ekrano la kunmetado plej ofte ne eblas. Sed temas ja nur pri kodo; presilo aŭ ekrano rajtas (se ĝi kapablas) por la tri simboloj "komo"+"retropaŝo"+"c" produkti belan c kun cedilo.
Estas bona kialo, ke en tiuj kunmetaĵoj la litero venas je la fino: Se en la aparato, kiu prezentas la signojn, retropaŝo forviŝas la lastan simbolon, estas pli bone, ke de "á" restu la "a" kaj ne nur la apostrofo/korno.
4.3.4 Veraj solvoj: aliaj signaroj
Por vere solvi la problemon de mankantaj signoj necesis krei signarojn, kiuj enhavis almenaŭ la signojn necesajn por iu certa lingvo. Principe estis tri ebloj por tio;
- La kreo de tute novaj signaroj, kompete malsamaj al Askio;
- La pligrandigo de Askio per uzo de pli ol 7 bitoj;
- La modifo de Askio per anstataŭigo de ne tro gravaj signoj.
La unua metodo estis preskaŭ ne uzata, ĉar neniu volis kodon, kiu ne enhavis la latinajn literojn kaj la eŭropajn ciferojn. La latinaj literoj necesis ne nur por reprezenti anglajn tekstojn, sed ankaŭ por kvazaŭ ĉiuj programad-lingvoj, tial neniu volis rezigni pri ili.
La dua metodo ŝajnis ideala, ĉar komputiloj normale storis ĉiun Aski-koderon en 8-bita bajto, do estis facile aldoni al Askio pliajn 128 koderojn. Tamen ankaŭ tiu metodo unue ne estis uzata, ĉar la 8-a bito estis jam uzata en multaj cirkonstancoj. Dum transsendo de datenoj inter komputilo tiu bito normale enhavis "parecan" informon; ĝi estis metita tiel, ke en ĉiu bajto la nombro de bitoj kun valoro "1" estis para. Tiel eblis rimarki teknikajn erarojn dum la transsendo (fuŝa modifo de bito kaŭzis, ke en bajto estis malpara nombro da bitoj kun valoro "1"). Pro tio retpoŝto devas speciale kodi ĉiujn ne-askiajn signojn. Ankaŭ la unuaj versioj de la Uniksa tekst-redaktilo "vi" ne kapablis trakti ne-Askiajn ok-bitajn signojn.
Restis la tria metodo. Kelkaj signoj en Askio estas difinitaj kiel ŝanĝeblaj, kaj por pluraj lingvoj ekzistas "alternativa" Askio, kiu aldifinas al tiuj kod-valoro alian signon. Tiujn alternativajn kodojn normigis ISO 646. Ekzemple:
4.3.2 Einfache Lösungen
Eine einfache, aber nicht wirklich befriedigende Lösung dieses Problems sind Ersatzsysteme, die nur ASCII-Zeichen verwenden. Solche Systeme gab es teilweise schon, um in solchen Sprachen international Telegramme versenden zu können. Beispiele sind:
- Manche Sprachen haben ein eingeführtes Ersatzsystem, das nur die englisch-lateinischen Grundbuchstaben verwendet. Zum Beispiel kann man auf Deutsch die Umlaute mit einem nachgestellten "e" schreiben: "ae" statt "ä", "oe" statt "ö", "ue" statt "ü".
- Manche Sprachen ersetzen die diakritischen Markierungen durch bestimmte nachgestellte Zeichen. Zum Beispiel kann man im Italienischen einen Apostroph statt eines Gravis benutzen: "a`" statt "à" usw.
- Manche Sprachen lassen die diakritischen Markierungen einfach weg; das erleichtert das Schreiben, erschwert aber das Lesen.
Sprachen mit nicht-lateinischer Schrift können ASCII nur mit Transliterierung verwenden.
4.3.3 Aufeinanderdrucken mehrerer Zeichen
Diakritische Zeichen sehen ungefähr aus,
als hätte man den lateinischen Grundbuchstaben genommen und
etwas darunter oder darüber gedruckt.
Daher kann man solche Zeichen darstellen, indem man zwei Zeichen an dieselbe
Stelle des Papiers druckt.
Um das zu erreichen, wurde ein Rückschritt eingefügt,
also das Zeichen, das auf der Schreibmaschine oft ein Pfeil nach links
(![]() ) darstellt. Hier einige Beispiele:
) darstellt. Hier einige Beispiele:
| á | ' | Apostroph statt Gravis |
| ä | " | Anführungszeichen statt Trema |
| ç | , | Komma statt Cedille |
Wenn man auf dem Papier die Zeichen so aufeinander druckt, sieht das Ergebnis nicht sehr schön aus; auf dem Bildschirm ist das Aufeinandersetzen meist nicht möglich. Aber es handelt sich ja nur um einen Kode; ein Drucker oder Bildschirm darf (wenn er es kann) statt der drei Symbole "Komma" + "Rückschritt" + "c" ein schönes ç mit Cedille erzeugen.
Es gibt übrigens einen Grund, warum man den Buchstaben in solchen Kombinationen an den Schluss schreibt: Wenn im Anzeigegerät der Rückschritt das letzte Symbol löscht, ist es besser, wenn von einem "á" das "a" stehen bleibt und nicht nur der Apostroph oder Akzent.
4.3.4 Echte Lösungen: andere Zeichensätze
Um das Problem der fehlenden Zeichen wirklich zu lösen, mussten Zeichensätze geschaffen werden, die zumindest alle notwendigen Zeichen für eine bestimmte Sprache enthalten. Grundsätzlich gibt es dafür drei Möglichkeiten:
- Die Schaffung ganz neuer Zeichensätze, die nichts mit ASCII zu tun haben;
- Die Erweiterung von ASCII durch Verwendung von mehr als 7 Bits;
- Die Modifikation von ASCII durch Ersetzung nicht so wichtiger Zeichen.
Die erste Methode wurde praktisch nicht verwendet, denn niemand wollte einen Kode ohne die lateinischen Buchstaben und die europäischen Ziffern. Die lateinischen Buchstaben sind nicht nur für englische Texte notwendig, sondern auch für fast alle Programmiersprachen, daher wollte niemand auf sie verzichten.
Die zweite Methode schien ideal, da Rechner gewöhnlich jedes ASCII-Zeichen in einem Byte mit 8 Bits speicherten, es war also leicht, dem ASCII-Kode weitere 128 Zeichen hinzuzufügen. Trotzdem wurde auch diese Methode zunächst nicht genutzt, da das 8. Bit in vielen Fällen bereits anders verwendet wurde. Bei der Übertragung von Daten zwischen Rechnern enthielt dieses Bit meistens "Paritäts"-Information: es wurde so gesetzt, dass in jedem Byte die Zahl der Bits mit dem Wert "1" gerade war. Dadurch ließen sich technische Fehler bei der Übertragung feststellen (eine fehlerhafte Veränderung eines Bits führt dazu, dass in einem Byte die Zahl der 1-Bits ungerade ist). Auch manche Programme verwendeten das 8. Bit für bestimmte Zusatzinformationen, zum Beispiel konnte der UNIX-Editor "vi" lange keine 8-Bit-Zeichen verarbeiten.
Es blieb die dritte Methode. Einige ASCII-Zeichen wurden als veränderbar definiert, mehrere Sprachen haben einen "eigenen ASCII-Kode", der diesen Kode-Werten ein anderes Zeichen zuweist. Diese alternativen Zeichensätze normiert die Norm ISO 646. Beispiele:
| Numeroj: | 35 | 36 | 64 | 91 | 92 | 93 | 94 | 96 | 123 | 124 | 125 | 126 | Nummern |
| Internacia | # | ¤ | @ | [ | \ | ] | ^ | ` | { | | | } | ~ | International |
| Askio | # | $ | @ | [ | \ | ] | ^ | ` | { | | | } | ~ | ASCII |
| Franca | £ | $ | à | ° | ç | § | ^ | ` | é | ù | è | ¨ | Französisch |
| Germana | # | $ | § | Ä | Ö | Ü | ^ | ` | ä | ö | ü | ß | Deutsch |
4.3.5 Ŝaltado inter kodoj
La uzo de tiaj lingvo-specifaj kodoj (precipe inter 1980 kaj 1990) signifis, ke francoj, germanoj ktp. ne povis uzi la ortajn kaj vostajn krampojn []{}, kiuj ja necesas por multaj programad-lingvoj. La afero ne estis granda problemo por programad-lingvaj tradukiloj, ĉar ili ne interesiĝis pri la kodo. Se franco tajpis "é13è", la tradukilo akceptis tion kiel "[13]". Sed por homoj tiaj programoj estis malbone legeblaj.
Principe oni ja povus uzi malsamajn kodojn por, ekzemple, leteroj kaj programoj, aŭ eĉ por diversaj partoj de tekst-dosiero. Tiun teknikon jam aplikis la teleksa kodo ("Baudot"-kodo, "Murray"-kodo), kiu per siaj 5 bitoj povis reprezenti nur 32 signojn kaj tamen havis (majusklajn) literojn, ciferojn kaj interpunkciojn. La ŝlosila tekniko estis la uzo de du kodoj kaj de trans-ŝaltaj stir-signoj, kiuj ŝaltas de la teksta kodo(parto) al la cifera-interpunkcia kaj inverse. Tiuj sub-kodoj estas nomataj "tavoloj".
Jena ekzemplo montras, kiel kodi la tekston "LA 15-A DE DECEMBRO 1859" en la Murray-kodo (CCITT-2). Klarigo: La unua linio montras en ruĝaj kampoj, kie okazas ŝalto al la litera tavolo (LIT) resp. al la cifera tavolo (CIF). La dua linio montras la interpreton en la litera tavolo kaj indikas per verda koloro, kie tiu tavolo efektive validas. La tria linio montras la interpreton en la cifera tavolo kaj indikas per verda koloro, kie tiu tavolo efektive validas. La inversa demandosigno (¿) indikas specialan stir-kodon, kiu funkciigas la sonorilon de teleksilo.
4.3.5 Umschalten zwischen Kodes
Die Verwendung solcher sprach-spezifischer Kodes (vor allem zwischen 1980 und 1990) bedeutete, dass Franzosen, Deutsche usw. die eckigen und geschweiften Klammern []{} nicht benutzen konnten. Das war für Übersetzer (Kompilierer) von Programmiersprachen kein großes Problem, da sie sich nicht für den Kode interessieren. Wenn ein Franzose "é13è" oder ein Deutscher "Ä13Ö" tippte, akzeptiert der Kompilierer das als "[13]". Aber für Menschen sind Programme auf diese Weise schlecht lesbar.
Im Prinzip ist es möglich, zum Beispiel für Briefe und für Programme verschiedene Kodes zu benutzen, oder sogar für verschiedene Teile einer einzigen Textdatei. Diese Technik wurde bereits im Fernschreib-Kode (Telex-Kode, Baudot-Kode, Murray-Kode) verwendet, der mit seinen 5 Bits nur 32 Zeichen darstellen konnte und trotzdem (Groß-)Buchstaben, Ziffern und Satzzeichen hatte. Die Schlüsseltechnik lag in der Verwendung von zwei getrennten Kodes und Steuerzeichen zur Umschaltung vom Text-Kode zum Kode für Ziffern und Satzzeichen und umgekehrt. Solche Teil-Kodes nennt man auch Kode-"Schichten".
Das folgende Beispiel zeigt, wie man den Text "LA 15-A DE DECEMBRO 1859" im Murray-Code (CCITT-2) kodiert. Erläuterung: Die erste Zeile zeigt in roten Feldern, wo ein Sprung in die Buchstaben-Schicht (LIT) bzw. in die Ziffern-Schicht (CIF) erfolgt. Die zweite Zeile zeigt die Interpretation in der Ziffernschicht und in grüner Farbe die Stellen, wo diese Schicht effektiv ist. Die dritte Zeile zeigt die Interpretation in der Buchstabenschicht und in grüner Farbe die Stellen, wo diese Schicht effektiv ist. Das umgekehrte Fragezeichen steht für einen besonderen Steuer-Kode, der die Glocke des Fernschreibers betätigt.
| LA | CIF | 15- | LIT | A DE DECEMBRO | CIF | 1859 | |
| Litera tavolo | LA | QTA | A DE DECEMBRO | QITO | |||
| Cifera tavolo | )- | 15- | - ¿3 ¿3:3.?49 | 1859 |
La tekniko de transŝalto inter diversaj kodoj do ekzistis delonge; Baudot evoluigis sian kodon en 1870 kaj Murray sian en 1901. La tekniko eĉ estis plivastigita al pliaj "tavoloj", greka kaj cirila. Tiu sama tekniko principe permesas ŝalti inter la diversaj variantoj de ISO 646, kvazaŭ ili estus tavoloj de unu sama, pli ampleksa kodo. Efektive la tekniko estis normigita per ISO 2022, kiu permesas ŝalti de japana, ĉina aŭ korea kodo al Askio kaj kelkaj aliaj kodoj.
Simila tekniko por ŝalti inter diversaj latinaj kodoj neniam estis normigita, aŭ eĉ nur iom vasta uzata. La kialo(j) estas unu el la historiaj enigmoj de informadiko; eble oni sentis veran bezonon.
La eblo, havi ne-Askiajn signojn kaj tamen konservi la tutan Aski-signaron, venis do nur per la ok-bitaj kodoj, normigitaj per ISO 8859. Ekzistas diversaj variantoj de tiu kodo, ĉar ankaŭ 256 signoj ne sufiĉas por kodi eĉ nur la signojn de la eŭropaj lingvoj:
- 8859/1 = "Latina 1": okcidenta Eŭropo
- 8859/2 = "Latina 2": centra/orienta Eŭropo
- 8859/3 = "Latina 3": suda Eŭropo (turka, malta, Esperanto
- 8859/4 = "Latina 4": norda Eŭropo
- 8859/5: cirila
- 8859/6: araba
- 8859/7: greka
- 8859/8: hebrea
- 8859/9 = "Latina 5": turka
- 8859/10 = "Latina 6": nordiaj lingvoj, 1992
- 8859/11 = taja
- 8859/12 (proponoj neniam normigitaj)
- 8859/13 = "Latina 7": balta
- 8859/14 = "Latina 8": kelta
- 8859/15 = "Latina 9": okcidenta Eŭropo, kun €
- 8859/16 = "Latina 10": sud-orienta Eŭropo, kun €
Sed ankaŭ ISO 8859 ne permesis ŝalton inter diversaj kodoj. Kiu uzas la cirilan varianton (5) de ISO 8859, ne povas uzi la francan signon "ç", ĉar ĝi estas nur en la variantoj 1, 2 kaj 3.
Jen tabeloj de ISO 8859-1 kaj ISO 8859-3.
Die Technik des Umschaltens zwischen verschiedenen Kodes oder Kodeschichten existierte also schon lange; Baudot entwickelte seinen Kode 1870 und Murray seinen 1901. Die Technik wurde sogar auf mehrere Schichten für griechisch und kyrillisch erweitert. Dieselbe Technik erlaubt grundsätzlich auch ein Umschalten zwischen verschiedenen Varianten von ISO 646, so als ob es Schichten ein und desselben, umfangreicheren Kodes wären. Tatsächlich wurde eine solche Technik unter ISO 2022 genormt; sie erlaubt ein Umschalten von japanischen, chinesischen und koreanischen Kodes zu ASCII und weiteren Kodes.
Eine solche Technik zur Umschaltung zwischen verschiedenen lateinischen Kodes wurde nie genormt oder auch nur in größerem Umfang verwendet. Die Gründe sind eines der historischen Rätsel der Informatik. Vielleicht wurde kein wirklicher Bedarf gesehen.
Die Möglichkeit, Nicht-ASCII-Zeichen zu haben und trotzdem alle ASCII-Zeichen zu behalten, kam also erst mit 8-Bit-Kodes, die unter ISO 8859 genormt wurden. Es gibt verschiedene Varianten davon, denn auch 256 Zeichen genügen nicht, um auch nur die Zeichen der europäischen Sprachen zu kodieren:
- 8859/1 = "Latin 1": Westeuropa
- 8859/2 = "Latin 2": Mittel-/Osteuropa
- 8859/3 = "Latin 3": Südeuropa (Türkisch, Maltesisch, Esperanto
- 8859/4 = "Latin 4": Nordeuropa
- 8859/5: kyrillisch
- 8859/6: arabisch
- 8859/7: griechisch
- 8859/8: hebräisch
- 8859/9 = "Latin 5": Türkisch
- 8859/10 = "Latin 6": nordische Sprachen, 1992
- 8859/11 = thailändisch
- 8859/12 (Vorschläge, nie zur Norm erhoben)
- 8859/13 = "Latina 7": baltisch
- 8859/14 = "Latina 8": keltisch
- 8859/15 = "Latina 9": Westeuropa mit €
- 8859/16 = "Latina 10": Südosteuropa mit €
Auch ISO 8859 erlaubt kein Umschalten zwischen verschiedenen Kodes. Wer die kyrillische Variante (5) von ISO 8859 verwendet, kann das französische Zeichen "ç" nicht verwenden, da es nur in den Varianten 1, 2 und 3 existiert.
Hier Tabellen der Zeichen von ISO 8859-1 und ISO 8859-3.
4.3.6 Interesa propono: Videotex
Kiam televidstacioj enkondukis la sistemon "Videotex", ili deziris havi je dispono laŭeble multajn simbolojn, sen ŝanĝi inter kodoj. Ili profitis de la eblo "kunmeti" diakritajn literojn, same kiel ISO 646 faris per retropaŝo. Ekestis nova kodo-normo ISO 6937, kiu tamen ne uzis retropaŝon, sed difinis 16 simbolojn, kiuj ĉiam kombiniĝas kun la sekva simbolo. Ili do funkcias kiel "morta klavo" en skribmaŝino, kiu tajpas signon, sed ne movas la ĉarumon.
La 16 diakritigaj simboloj de ISO 6937 estas:
4.3.6 Ein interessanter Vorschlag: Videotex
Als die Fernsehstationen das System "Videotex(t)" einführten, wollten sie gerne möglichst viele Symbole haben, ohne zwischen Kodes umschalten zu müssen. Sie nutzten die Möglichkeit, diakritische Zeichen zu Buchstaben hinzuzufügen, wie es ISO 646 mit dem Rückschritt macht. Es entstand eine neue Norm ISO 6937, die aber keinen Rückschritt benutzt, sondern 16 Symbole definiert, die immer mit dem folgenden Zeichen verschmelzen. Sie funktionieren also wie eine "tote Taste" auf der Schreibmaschine, die ein Zeichen tippt, ohne den Wagen weiterzubewegen.
Die 16 diakritischen Zeichen von ISO 6937 sind:
| nomo | kodo | ekzemplo | |
|---|---|---|---|
| Kode | Beispiel | Name | |
| dekstra korno | 193 | `a = à | Gravis |
| maldekstra korno | 194 | ´a = á | Akut |
| ĉapelo | 195 | ^a = â | Zirkumflex |
| tildo | 196 | ~a = ã | Tilde |
| supera streko | 197 | ‾a = Ā | Überstrich (macron) |
| hoketo | 198 | ua = ă | Breve |
| supera punkto | 199 | ·c = ċ | Punkt oben |
| supera dupunkto | 200 | ¨a = ä | Trema |
| suba punkto | 201 | .b = ḅ | Punkt unten |
| supera ringo | 202 | °a = å | Ring oben |
| cedilo | 203 | ¸c = ç | Cedille |
| suba streko | 204 | Strich unten | |
| hungara duobla korno | 205 | "o = ő | Doppelakut |
| ogoneko | 206 | ,a = ą | Ogonek |
| haĉeko | 207 | ve = ě | Hatschek |
4.3.7 La fina (?) solvo: Unikodo
Ĉiuj priskribitaj solvoj estas aŭ estis aplikataj, sed neniu vere universale. Tiel ekestis problemoj ĉe interŝanĝo de datenoj. Necesis vere universala solvo.
Tiu solvo nun ŝajnas trovita, ĝi nomiĝas Unikodo (angle: Unicode). Versio 3.2 de Unikodo enhavis 95.156 signojn, versio 4.0 96.382. Intertempe ekzistas versio 4.1, kiu havas 97.655. La unuaj 128 signoj de Unikodo estas identaj kun tiuj de Askio, la unuaj 256 kun tiujn de ISO 8859/1. Unikodo do estas kongrua kun tiuj kodoj. Estas tre facile transformi datenojn el tiuj kodoj al Unikodo. Ĉe aliaj kodoj tio estas iom malpli facila. Unikodo difinas nur kod-numerojn por signoj, sed ne, kiel oni prezentas tiujn numerojn, ekzemple en bajto-vico. Sed estas klare, ke ne eblas kodi ĉiujn unikodajn signojn en po unu bajto. Eĉ du bajtoj ne sufiĉas, ĉar ili povas havi nur 65.536 malsamajn valorojn. Por kodi Unikodon kun fiksa kod-longo oni uzas kvar bajtojn, ĉar Unikodo permesas vastigon al 221 signoj. Tiu kvar-bajta prezentado nomiĝas UTF-32 (unikoda transforma aranĝo 32). Ekzistas du pliaj gravaj prezentad-manieroj: UTF-16, ĉe kiu unu signo okupas inter 2 kaj 4 bajtoj, kaj UTF-8, ĉe kiu unu signo okupas inter 1 kaj 6 bajtoj. UTF-16 estas uzata ekzemple de la programad-lingvo Ĝavo (Java).
Unikodo ebligas ne nur reprezentadon de signoj el preskaŭ ĉiuj lingvoj, sed ankaŭ mikslingvajn tekstojn.
4.3.7 Die endgültige (?) Lösung: Unicode
Alle beschriebenen Lösungen werden oder wurden praktisch eingesetzt, aber keine wirklich universell. Daher kam es zu Problemen beim Datenaustausch. Eine wirklich universelle Lösung wurde gebraucht.
Diese Lösung scheint jetzt gefunden zu sein, sie heißt Unicode. Version 3.2 von Unicode enthielt 95.156 Zeichen, Version 4.0 96.382. Inzwischen gibt es Version 4.1, die 97.655 Zeichen enthält. Die ersten 128 Zeichen von Unicode sind identisch mit denen von ASCII, die ersten 256 mit denen von ISO 8859-1. Unicode ist also mit diesen Kodes kompatibel. Es ist leicht, Daten in dieses Kodes in Unicode umzuwandeln. Bei anderen Kodes ist es etwas schwieriger.
Unicode definiert nur Kodenummern für Zeichen, jedoch keine Darstellung dieser Kodenummern, etwa als Byte-Folge. Klar ist, dass man nicht alle Unicode-Zeichen in einem Byte kodieren kann; auch zwei Bytes reichen nicht aus, da sie maximal 65.536 Zeichen kodieren können. Zur Kodierung von Unicode mit fester (einheitlicher) Kodelänge verwendet man vier Bytes, da Unicode eine Erweiterung auf 21 Bits zulässt und früher sogar noch mehr erlaubte. Diese Kodierung (engl. encoding) heißt UTF-32. In der Praxis sind zwei andere Kodierungen wichtiger, die keine feste Kodelänge haben: Bei UTF-16 belegt ein Unicode-Zeichen zwischen 2 und 4 Bytes, bei UTF-8 zwischen 1 und 6 Bytes. UTF-16 wird zum Beispiel in der Programmiersprache Java benutzt.
Mit Unicode lassen sich nicht nur Zeichen praktisch aller Sprachen darstellen, es sind auch gemischtsprachige Texte problemlos möglich.
4.3.8 Signaroj vivas
Fina rimarkigo: Lingvoj kaj skriboj evoluas, kaj la signaroj ŝanĝiĝas. Jen du ekzemploj: Ĉirkaŭ 1990 ukrainoj memoris, ke iam ili havis du formojn de la litero G (Γ, Ґ); Stalin estis foriginta la duan formon. Kaj fine de la 20-a jarcento ekestis la nova signo "€" por eŭro, antaŭe ne nur nekonata, sed neekzistinta. En la ĉina lingvo regule ekestas novaj signoj. Precipe la universala signaro Unikodo devas adaptiĝi al tiaj ŝanĝoj.
4.3.8 Zeichensätze leben
Schlussbemerkung: Sprachen und Schriften entwickeln sich, und Zeichensätze ändern sich. Hier zwei Beispiele: Im Jahr 1990 erinnerten sich die Ukrainer daran, dass sie früher zwei Formen des Buchstabens "G" hatten (Γ, Ґ); Stalin hatte die zweite Form abgeschafft. Ende des 20. Jahrhunderts entstand das neue Zeichen "€" für den Euro, das vorher nicht nur unbekannt war, sondern gar nicht existierte. Im Chinesischen entstehen regelmäßig neue Zeichen. Vor allem der universelle Kode Unicode muss sich an solche Änderungen anpassen.
4.4 Skribdirekto
Latinskribaj lingvoj ordinare skribas en linioj de maldekstre dekstren kaj aranĝas la liniojn de supre malsupren sur paĝo. Sed principe eblas ankaŭ la inversaj aranĝoj. Eĉ ekzistas altern-direkta skribo ("kiel pluganto sur agro"), kiu post ĉiu linio ŝanĝas la skribdirekton kaj komencas sub la fino de la antaŭa linio.
Konataj ekzemploj de lingvoj, kiuj skribas de dekstre maldekstren, estas la araba kaj la hebrea. La ĉina, mongola kaj japana lingvo tradicie skribas plej ofte vertikale, sed sub influo de okcidenta kulturo (kaj tekniko) uzas ankaŭ horizontalan skribon.
Se programo lasas la aranĝon de tekstoj al presilo, ekrano aŭ al alia programo, ĝi povas ignori la skribdirekton. Sed programoj, kiuj mem aranĝas tekstojn, devas konsideri ĝin. Kaj la skribdirekto validas ne nur interne de frazo, sed ankaŭ inter diversaj tekstpartoj, ekzemple kampo por teksto-enigo kaj ĝia etikedo.
Kiel ekzemplon imagu programon, kiu prezentas serĉo-dialogon kun tri elementoj:
- La etikedon "serĉo-vorto"
- Teksto-kampon por enigo de la vorto
- butonon kun la teksto "serĉu"
Programo kun latinskriba "gepatra lingvo" verŝajne emas doni al tiuj tri elementoj fiksajn poziciojn de maldekstre dekstren, sed en araba versio necesas aranĝi ilin de dekstre maldekstren. Tion montras la ekzemplo de serĉo-dialogo de Vikipedio, en la lingvoj rumana kaj araba:
4.4 Schreibrichtung
Sprachen mit lateinischer Schrift schreiben gewöhnlich in Zeilen von links nach rechts und ordnen die Zeilen von oben nach unten auf der Seite an. Aber grundsätzlich ist auch die umgekehrte Anordnung möglich. Es gibt sogar die Möglichkeit einer abwechselnden Schreibrichtung ("Bustrophedon", wie ein Pflug auf dem Acker), die nach jeder Zeile die Schreibrichtung ändert und unter dem Zeilenende der vorhergehenden Zeile beginnt.
Bekannte Beispiele von Sprachen, die von rechts nach links schreiben, sind Arabisch und Hebräisch. Chinesisch, Mongolisch und Japanisch schreiben traditionell meist von oben nach unten, verwenden aber unter dem Einfluss der abendländischen Kultur (und Technik) auch die waagerechte Schreibung.
Wenn ein Programm die Anordnung von Texten einem Drucker, einem Bildschirm oder einem anderen Programm überlässt, kann es die Schreibrichtung ignorieren. Aber Programme, die selbst Texte ausrichten, müssen sie in Betracht ziehen. Und die Schreibrichtung gilt nicht nur innerhalb eines Satzes, sondern auch zwischen verschiedenen Textteilen, zum Beispiel einem Eingabefeld für Text und seiner Beschriftung.
Stellen Sie sich als Beispiel ein Programm vor, das einen Such-Dialog mit drei Bestandteilen anzeigt:
- Die Beschriftung "Suchwort"
- Ein Textfeld für die Eingabe des Suchworts
- eine Schaltfläche mit dem Text "Suchen"
Ein Programm mit einer lateinisch geschriebenen Muttersprache neigt vermutlich dazu, diesen drei Bestandteilen von links nach rechts feste Positionen zuzuordnen. In einer arabischen Version muss die Anordnung jedoch umgekehrt erfolgen. Das zeigt das Beispiel eines Such-Dialogs aus der Wikipedia, auf Rumänisch und auf Arabisch:
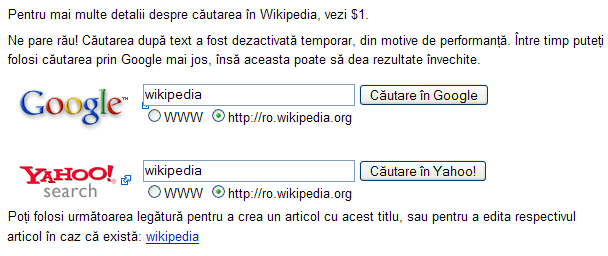
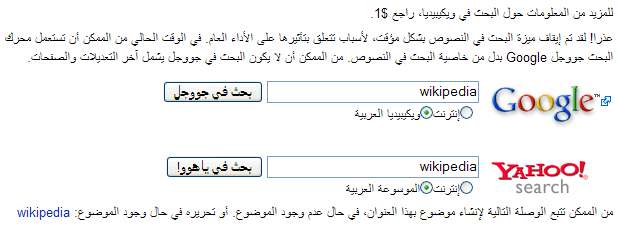
Aparta problemo de malsamaj skribdirektoj estas, ke skribdirektoj povas miksiĝi. En lingvoj skribataj de dekstre maldekstren tio ofte okazas, ĉar ili enhavas signojn kun mala skribdirekto, ekzemple ciferojn aŭ alilingvajn vortojn. Estas rekomendinde, ke programoj lasu tiujn detalojn al iu kadraĵo, ekzemple al ret-krozilo, se temas pri reta programo. Modernaj ret-kroziloj nun sufiĉe bone traktas tiujn problemojn. Jen ekzemplo de hebrea teksto kun numerita listo; la tri-ŝtupaj numeroj aspektas same kiel en latin-litera teksto:
Ein besonderes Problem unterschiedlicher Schreibrichtungen ist, dass sich Schreibrichtungen mischen können. In Sprachen, die von rechts nach links geschrieben werden, passiert das oft, weil sie Zeichen mit entgegengesetzter Schreibrichtung enthalten können, zum Beispiel Ziffern oder Wörter aus anderen Sprachen. Es empfiehlt sich, dass Programme solche Besonderheiten einem geeigneten Rahmen überlassen, zum Beispiel einem Netz-Browser, wenn es sich um ein netz-basiertes Programm handelt. Moderne Browser behandeln solche Problemfälle recht gut. Hier als Beispiel ein hebräischer Text mit einer nummerierten Liste; die dreistufigen Nummern sehen so aus wie in einem lateinisch geschriebenen Text:

4.5 Tradukado de signoj kaj simboloj
Oni emas kredi, ke bildoj kaj simboloj ne bezonas tradukadon aŭ internaciigon, sed ankaŭ ili povas dependi de lingvo aŭ kulturo. Simpla kazo estas sagoj en teksto, kiuj ofte devas esti inversigitaj, se la lingvo havas alian skrib-direkton.
Ankaŭ interpunkcioj principe bezonas tradukon. Ekzemple citiloj tre diferencas inter lingvoj. Krome kelkaj lingvoj uzas citilojn por la rekta parolo, aliaj uzas enkondukon per longa streko (–). Se citiloj estas uzataj, fina komo povas esti antaŭ (angla lingvo) aŭ post (germana lingvo) la ferma citilo.
4.5 Übersetzung von Zeichen und Symbolen
Man neigt dazu, anzunehmen, dass Bilder und Symbole nicht übersetzt
oder internationalisiert zu werden brauchen, aber auch sie können
sprach- oder kulturabhängig sein.
Ein einfacher Fall sind Pfeile in Texten,
die oft umgedreht werden müssen,
wenn die Sprache eine andere Schreibrichtung hat
(127![]() 128,
۱۲۸
128,
۱۲۸![]() ۱۲۷).
۱۲۷).
Auch Satzzeichen müssen übersetzt werden. Zum Beispiel unterscheiden sich Anführungszeichen sehr zwischen den Sprachen. Außerdem benutzen manche Sprachen Anführungszeichen für die direkte Rede, andere einen vorangestellten Gedankenstrich (–). Wo Anführungszeichen benutzt werden, kann ein abtrennendes Komma vor (Englisch) oder nach (Deutsch) dem schließenden Anführungszeichen stehen.
| Rumana | „xyz“ | Rumänisch |
|---|---|---|
| Germana | „xyz“ | Deutsch |
| Germana | »xyz« | Deutsch |
| Angla | “xyz” | Englisch |
| Franca | «xyz» | Französisch |
| Rumana | – Evident, respinse Radu. | Rumänisch |
|---|---|---|
| Germana | „Offensichtlich“, antwortete Radu. | Deutsch |
| Angla | “Obviously,” Radu replied. | Englisch |
4.6 Kulturaj diferencoj
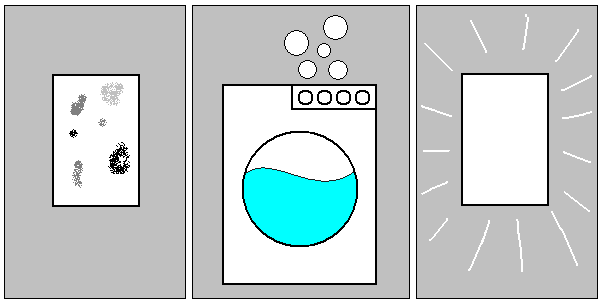
Kulturaj diferencoj, kiuj koncernas pli ol la lingvon, estas tre malfacile antaŭvideblaj kaj trakteblaj. Kelkaj tamen rilatas al la lingvo; ekzemple la skribdirekto influas ankaŭ la manieron, legi bildstrion. Konata ŝerco estas, ke firmao pri lavmaŝinoj faras "internacian" reklam-bildon sen vortoj, kiu montras unue (maldekstre) malpuran tukon, poste lavmaŝinon kaj fine puran tukon. La firmao tre miras, ke ĝi nenion vendas en arab-lingvaj landoj:
4.6 Kulturelle Unterschiede
Kulturelle Unterschiede, die mehr als die Sprache betreffen, sind schwer vorherzusehen und zu berücksichtigen. Manche haben allerdings Bezug zur Sprache; zum Beispiel beeinflusst die Schreibrichtung auch die Art, wie eine Bildergeschichte gelesen wird. Ein bekannter Witz erzählt, dass eine Firma für Waschmaschinen ein "internationales" Reklamebild ohne Worte entwirft, das zuerst (links) ein schmutziges Tuch, dann eine Waschmaschine und zuletzt ein sauberes Tuch zeigt. Die Firma wundert sich dann, dass sie in arabisch sprechenden Ländern nichts verkauft:
Estas bona instruo kompari arablingvajn kaj latin-literajn retpaĝojn. Bona okazo estas Vikipedio. Jen bildo el la artikoloj pri la urbo Mekao en la araba kaj en Esperanto:
Es ist lehrreich, arabische und lateinisch geschriebene WWW-Seiten miteinander zu vergleichen. Dazu bietet die Wikipedia eine gute Gelegenheit. Hier ein Bild von Artikeln zur Stadt Mekka aus der arabischen und der Esperanto-Wikipedia:
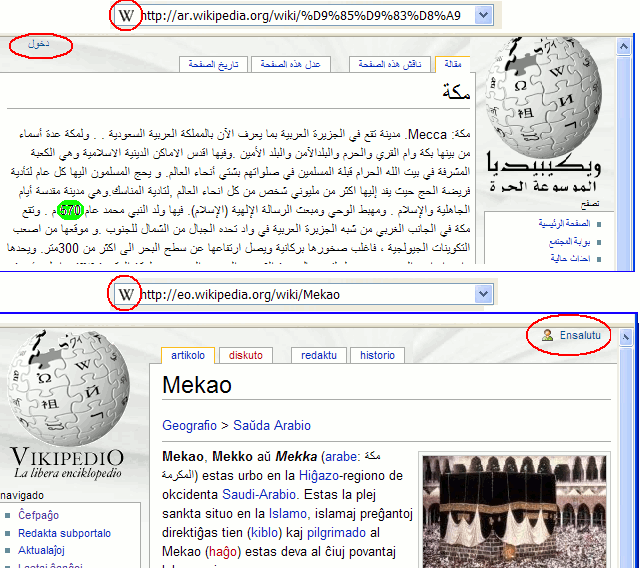
- La araba teksto uzas ne la malnovajn arabajn, sed la eŭrop-arabajn ciferojn. Pro la komputilo kaj la influo de aliaj kulturoj araboj kutimiĝis al tiuj ciferoj.
- La litero "W", simbolo de Vikipedio, ne estas tradukita.
- La araba paĝo ne enhavas bildojn, verŝajne ĉar Islamo malpermesas fari bildojn de personoj. Tio eĉ kaŭzas, ke la eta homfiguro supre ĉe la vorto "Ensalutu", kiu simbolas la uzulon, mankas en la araba versio.
- Der arabische Text verwendet nicht die alten arabischen, sondern die europäisch-arabischen Ziffern. Durch den Computer und unter dem Einfluss anderer Kulturen haben sich die Araber an diese Ziffern gewöhnt.
- Der Buchstabe "W" als Symbol der Wikipedia wird nicht übersetzt.
- Der arabische Artikel enthält keine Bilder, vermutlich, weil der Islam verbietet, Bilder von Menschen zu machen. Das führt sogar dazu, dass das kleine Männchen oben neben dem Wort "Anmelden" (Ensalutu), das den Benutzer symbolisiert, in der arabischen Version fehlt.
Specimenaj demandoj:
- Kial estas problemo, se teksto havas malsaman longecon en diversaj lingvoj?
- Kial povas esti problemo, se ekestas nova versio de programo?
- Per kiuj kodoj eblas reprezenti la literojn de la angla lingvo?
- Kiom da bitoj bezonas unu signo de Askio?
- Kiom da bitoj bezonas unu signo de ISO 8859/1?
- Kie internaciigita programo havas siajn mesaĝo-tekstojn?
- Donu ekzemplon por du lingvoj kun malsamaj skribdirektoj!
Beispielfragen:
- Warum ist es ein Problem, wenn ein Text in verschiedenen Sprachen unterschiedliche Länge hat?
- Warum kann es ein Problem sein, wenn eine neue Version eines Programms erscheint?
- Mit welchen Kodes kann man die Buchstaben der englischen Sprache darstellen?
- Wie viele Bits braucht ein ASCII-Zeichen?
- Wie viele Bits braucht ein ISO-8859/1-Zeichen?
- Wo hat ein internationalisiertes Programm seine Meldungstexte?
- Geben Sie ein Beispiel für zwei Sprachen mit unterschiedlicher Schreibrichtung!