3 Principoj de maŝina tradukado
3 Grundlagen der maschinellen Übersetzung
3.6 Korpuse bazitaj aliroj
3.6 Korpus-basierte Ansätze
Ĉirkaŭ 1990 oni ekesploris novajn alirojn en MT, kiuj baziĝis sur la ekspluato de tradukaj "korpusoj", grandaj kvantoj da tradukita materialo komputile disponebla. La nova ideo estis, ke traduksistemo aŭtomate "lernu" el tiu materialo, anstataŭ uzi fiksan aron da tradukaj reguloj.
Ne estis mirige, ke tiu aliro ne estis uzata en la komenca tempo de MT. Tiaj plurlingvaj korpusoj iĝis disponeblaj nur, kiam tradukistoj grandskale ekuzis komputilojn por tajpado. (Inter la unuaj korpusoj uzataj estis la dulingvaj protokoloj de la Kanada parlamento, redaktitaj en la Angla kaj Franca lingvoj.)
Um 1990 begann man mit der Erforschung neuer Ansätze in der MÜ, die auf der Nutzung von Übersetzungs-"Korpora" beruhten, also großen Mengen übersetzten Materials, das zwei- oder mehrsprachig maschinenverwendbar vorliegt. Der neue Gedanke war, dass ein Übersetzungssystem aus diesem Material automatisch "lernen" sollte, statt einen festen Satz von Übersetzungsregeln zu verwenden.
Es ist nicht verwunderlich, dass dieser Ansatz in der Anfangszeit der MÜ nicht verwendet wurde. Solche mehrsprachigen Korpora waren erst verfügbar, als die Übersetzer zum Tippen ihrer Arbeit verbreitet Rechner benutzten. (Zu den ersten verwendeten Korpora gehörten die Protokolle des kanadischen Parlaments, die auf Englisch und Französisch verfasst werden.)
Kvankam ekzistas pli-ol-du-lingvaj korpusoj (precipe el la tradukservoj de Eŭropa Unio), la nunaj esploroj ŝajnas koncentriĝi al dulingvaj sistemoj. Estas malfacile imagi, kiel oni povus apliki la korpusan aliron al pontolingva sistemo. Tial la korpuse bazitaj sistemoj plejparte koncentriĝas al "gravaj" lingvo-paroj. Aliflanke la baza strukturo de tiaj sistemoj ne dependas de konkretaj lingvoj, tial oni povas facile trejni tian sistemon al nova lingvo-paro, se oni disponas korpuson por ĝi.
Obwohl Korpora mit mehr als zwei Sprachen existieren (vor allem aus den Übersetzungsdiensten der Europäischen Union), scheinen sich die Forschungen auf zweisprachige Systeme zu konzentrieren. Es ist schwer vorstellbar, wie man den Korpus-Ansatz auf ein brückensprachliches System anwenden könnte. Daher konzentrieren sich die korpus-basierten Systeme überwiegend auf "wichtige" Sprachenpaare. Andererseits hängt die Grundstruktur solcher Systeme nicht von konkreten Sprachen ab; daher kann man ein solches System leicht auf ein neues Sprachenpaar trainieren, wenn ein entsprechender Korpus verfügbar ist.
3.6.1 Statistika aliro
3.6.1 Statistischer Ansatz
Unu nova aliro, ekesplorata ĉirkaŭ 1990, radikale kontraŭis la ĝistiaman konvinkon, ke por traduki necesas analizi la strukturon de la tradukata teksto. La nova paradigmeto eliris de la fakto, ke por ĉiu fontolingva frazo f kaj ĉiu cellingva frazo c ekzistas probablo, ke c estas uzata kiel traduko de f. Tiu probablo estas statistike esprimebla kiel la kondiĉa probablo p(c|f), do la "probablo de c sub la kondiĉo f". Tiaj probabloj estas determineblaj el dulingva korpuso.
Einer der neuen Ansätze, dessen Eerforschung um 1990 begann, richtete sich radikal gegen die traditionelle Überzeugung, zum Übersetzen müsse man die Struktur des zu übersetzenden Textes analysieren. Das neue Prinzip ging von der Tatsache aus, dass es für jedem Satz f der Ausgangssprache und jedem Satz c der Zielsprache eine Wahrscheinlichkeit gibt, dass c als Übersetzung von f verwendet wird. Diese Wahrscheinlichkeit lässt sich statistisch ausdrücken als die bedingte Wahrscheinlichkeit p(c|f), also die "Wahrscheinlichkeit von c unter der Bedingung f". Solche Wahrscheinlichkeiten lassen sich aus einem zweisprachigen Korpus bestimmen.
La strategio estas uzi kiel tradukon por donita fonto-lingva frazo f tiun cel-lingvan frazon c, kies kondiĉa probablo p(c|f) estas plej alta inter ĉiuj cel-lingva frazoj. Nek sintaksaj reguloj nek semantika scio estas uzataj.
Erstaunlicherweise stellte sich heraus, dass solche Systeme, die wenig von der Struktur eines Textes verstehen, befriedigend übersetzen können. Letzteres bewiesen vergleichende Untersuchungen in den Jahren 1992-1994, die dem System CANDIDE (von IBM) vergleichbare Fähigkeiten bescheinigten wie den besten herkömmlichen Systemen.
Kiom bone statistikaj sistemoj povas "kompreni" la strukturon de tekstoj, videblas el la fakto, ke ili kapablas strukture "paraleligi" frazon kun ĝia traduko. Tiu paraleligo estas atribuado inter la vortoj de la du frazoj. Pro la malsama vort-ordo kaj pro tradukado de unu vorto per pluraj aŭ inverse tiu paraleligo ne estas triviala, kiel montras la sekva ekzemplo (Franca-Germana):
Wie gut statistische Systeme die Struktur von Texten "verstehen" können, ergibt sich aus der Tatsache, dass sie einen Satz strukturell an seiner Übersetzung "ausrichten" können. Diese Ausrichtung ist eine Zuordnung zwischen den Wörtern der beiden Sätze. Wegen der unterschiedlichen Wortstellung und weil ein Wort durch mehrere Wörter übersetzt werden kann und umgekehrt, ist diese Ausrichtung nicht trivial, wie das folgende (französisch-deutsche) Beispiel zeigt:
Der Präsident möchte dazu zur Zeit nicht Stellung nehmen.
Actuellement, le président ne veut pas s'y prononcer.
| Der | Präsident | möchte | dazu | zur | Zeit | nicht | Stellung | nehmen | |
|---|---|---|---|---|---|---|---|---|---|
| Actuellement | x | x | |||||||
| le | x | ||||||||
| président | x | ||||||||
| ne | x | ||||||||
| veut | x | ||||||||
| pas | x | ||||||||
| s' | x | x | |||||||
| y | x | ||||||||
| prononcer | x | x |
La trairo tra tiu paraleliga matrico laŭ la Germana aŭ laŭ la Franca vort-ordo rezultigas jenajn zigzagajn vojojn:
Wenn man diese Ausrichtungsmatrix nach der deutschen oder nach der französischen Wortreihenfolge durchläuft, ergeben sich zwei verschiedene Zickzack-Wege:
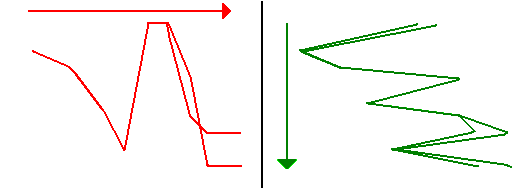
Statistikaj traduk-sistemoj kapablas, surbaze de donitaj frazo-limoj, paraleligi frazojn kun ties tradukoj, se disponeblas sufiĉe ampleksa korpuso.
Statistische Übersetzungssysteme sind in der Lage, auf der Basis gegebener Satzgrenzen Sätze nach ihren Übersetzungen auszurichten, wenn ein genügend umfangreicher Korpus zur Verfügung steht.
Se statistika sistemo havas almenaŭ unu eblan tradukon por tradukenda frazo, ĝi povas provizi tradukon. Se ne, ĝi devas trovi alian solvon; ekzemple ĝi povas serĉi tradukojn por frazopartoj kaj kunmeti ilin al traduko de la frazo. Tiel, en ekstrema okazo, ni revenas al vort-post-vorta traduko, kiu donas malbonajn rezultojn, pro jenaj fenomenoj:
Wenn ein statistisches System zumindest eine mögliche Übersetzung für einen gegebenen Satz kennt, kann es eine Übersetzung anbieten. Wenn nicht, muss es eine andere Lösung finden; zum Beispiel kann es Übersetzungen für Teile des Satzes suchen und sie zu einer Übersetzung des ganzen Satzes zusammensetzen. Das führt im Grenzfall zur Übersetzung Wort für Wort, bei der folgende Erscheinungen für schlechte Ergebnisse sorgen:
- Vortoj ofte havas plurajn signifojn (ambigueco).
- Unu vorto povas esti tradukata per unu aŭ pluraj vortoj, eĉ per neniu vorto. La nombro de la vortoj en la traduko nomiĝas la fekundeco de la vorto. En la supra ekzemplo la fekundeco de la Germana vorto "nicht" estas 2 (traduko per "ne ... pas").
- La pozicio de la inter-respondaj vortoj en la frazo estas malsama en diversaj lingvoj. Tio nomiĝas distordo de frazoj.
- Wörter haben oft mehrere Bedeutungen (Mehrdeutigkeit).
- Ein Wort kann durch ein, mehrere oder gar kein Wort übersetzt werden. Die Zahl der Wörter in der Übersetzung des Worts heißt seine Fruchtbarkeit. Im obigen Beispiel ist die Fruchtbarkeit des deutschen Worts "nicht" gleich 2 (es wird durch "ne ... pas" übersetzt).
- Die Position entsprechender Wörter im Satz ist in verschiedenen Sprachen unterschiedlich. Dieses Phänomen heißt Verzerrung des Satzes.
Ankaŭ tiuj tri fenomenoj posedas probablojn; ekzemple por la distordo ekzistas probabloj, ke la traduko de la 1a, 2a, 3a ... vortoj en fontolingva frazo estas la 1a, 2a, 3a ... vorto en la cellingva frazo. Per tiuj probabloj la statistika tradukado iĝas multe pli preciza ol nura laŭvorta traduko.
Auch für diese drei Erscheinungen lassen sich Wahrscheinlichkeiten ermitteln; zum Beispiel existieren für die Verzerrung Wahrscheinlichkeiten, dass die Übersetzung des 1., 2., 3... Wortes im Satz der Ausgangssprache das 1., 2., 3... Wort im Satz der Zielsprache ist. Mit dieses Wahrscheinlichkeiten wird die statistische Übersetzung wesentlich genauer als eine bloße Wort-für-Wort-Übersetzung.
3.6.2 Tradukado per ekzemploj
3.6.2 Übersetzung anhand von Beispielen
Tradukado per ekzemploj (ekzemplo-bazita tradukado) apogas sin, same kiel statistikaj metodoj, sur korpuso da dulingvaj tekstoj. Male al statistika tradukado ĝi klopodas apliki iun lingvistikan scion. Se tiuspeca traduka sistemo trovas plurajn eblajn tradukojn por unu vorto, ĝi aplikas regulojn por trovi la plej taŭgan por la aktuala kazo. Por tio ĝi povas uzi informon pri proksimaj vortoj (semantiko) aŭ pri la gramatika strukturo de la frazo (sintakso).
Die Übersetzung anhand von Beispielen (beispiel-basierte Übersetzung) stützt sich, ebenso wie statistische Methoden, auf einen Korpus zweisprachiger Texte. Im Gegensatz zur statistischen Übersetzung versucht sie, ein gewisses linguistisches Wissen anzuwenden. Wenn ein solches Übersetzungssystem mehrere mögliche Übersetzungen für ein Wort findet, wendet es Regeln an, um die im gegebenen Fall geeignetste zu finden. Dazu kann es Informationen über in der Nähe stehende Wörter (Semantik) oder über die grammatikalische Struktur des Satzes (Syntax) verwenden.
La principaj ideoj aperis jam longe antaŭ 1990 kaj eliris de la supozo, ke homaj tradukantoj ofte uzas scion pri iam tradukitaj "similaj" tekstoj kaj tradukas "analoge" al tiaj "ekzemploj". La demando estas, kiel formale difini similecon kaj analogecon.
Die Grundideen tauchten bereits lange vor 1990 auf und gingen von der Annahme aus, dass menschliche Übersetzer häufig Wissen über früher übersetzte "ähnliche" Texte nützen und "analog" zu solchen "Beispielen" übersetzen. Die Frage ist, wie sich Ähnlichkeit und Analogie formal definieren lassen.
La principo de traduko per ekzemploj estas simpla: Se (el la korpuso) por iu teksto-parto estas konata traduko ("ekzemplo"), uzu ĝin. Tio funkcias sufiĉe bone, se la teksto-parto estas kompleta frazo. Aliflanke, se la teksto-partoj estas unuopaj vortoj, rezultas vort-post-vorta traduko, kun siaj konataj problemoj. Ĉar ne tre ofte kompletaj donitaj frazoj estas trovataj en la uzata korpuso, necesas fari kompromison kaj trovi laŭeble plurvortajn fraz-partojn (ne nepre sintagmojn).
Das Prinzip der Übersetzung anhand von Beispielen ist einfach: Wenn (aus dem Korpus) für einen Textteil eine Übersetzung (ein "Beispiel") bekannt ist, wird sie verwendet. Das funktioniert gut, wenn der Textteil ein vollständiger Satz ist. Wenn andererseits die Textteile einzelne Wörter sind, kommt es zur Übersetzung Wort für Wort, mit ihren bekannten Problemen. Da sich nicht sehr oft ein vollständiger gegebener Satz im Korpus findet, ist ein Kompromiss nötig, bei dem möglichst Satz-Stücke (nicht unbedingt komplette Satzteile) aus mehreren Wörtern gefunden werden.
Ni rekonsideru la Zamenhofan ekzemplon el la Germana: "Ich weiß nicht, wo ich meinen Stock gelassen habe." Ĉiuj kvar ĝiaj ambiguecoj estas facile solveblaj per duvortaj ekzemploj. (La lasta kolumno de la tabelo nombras la eblajn signifojn.)
Betrachten wir nochmals Zamenhofs Beispiel "Ich weiß nicht, wo ich meinen Stock gelassen habe." Alle vier Mehrdeutigkeiten lassen sich mit Beispielen aus zwei Wörtern leicht auflösen. (Die letzte Spalte der Tabelle zeigt die Zahl der möglichen Bedeutungen.)
| weiß | blanka; scias | Farbe; wissen, 1. Person | 2 |
|---|---|---|---|
| ich weiß | mi scias | wissen, 1. Person | 1 |
| meinen | opinii; pensi; mian | Verb; Possesivpronomen | 2 |
| meinen Stock | mian bastonon | Possesivpronomen | 1 |
| Stock | bastono; etaĝo | Stab; Stockwerk | 2 |
| meinen Stock | mian bastonon | Stab | 1 |
| gelassen | trankvila; lasinta | ruhig; lassen, Partizip Perfekt | 2 |
| gelassen habe | lasis | lassen, Perfekt | 1 |
Estas notinde, ke la ambigueco de "Stock" (bastono; etaĝo) ne estas (male al la aliaj tri) solvebla gramatike. Sed tiu vorto estas uzata en la signifo "etaĝo" preskaŭ nur post vicmontraj nombroj (unua, dua ktp. etaĝo), do ĝi ne aperus en korpuso post la pronomo "meinen".
3.6.3 Problemoj de korpusaj sistemoj
3.6.2 Probleme korpus-basierter Systeme
Malgraŭ siaj sukcesoj, korpusaj problemoj havas ankaŭ problemojn. Unue, la paraleligo de fontaj kaj celaj tekstoj normale limiĝas al frazoj, laŭ la supozo, ke unu frazo tradukiĝas al unu frazo. Sed tiel perdiĝas ĉia informo pri la "antaŭaĵoj" de pronomoj, kaj se ekzemple la cellingvo havas plurajn (genre ktp.) malsamajn pronomojn por unu fontolingva pronomo, ne eblas solvi tiun ambiguecon.
Trotz ihrer Erfolge haben korpus-basierte Systeme auch ihre Probleme. Zunächst beschränkt sich die Parallelisierung von Ausgangs- und Zieltexten gewöhnlich auf Sätze, nach der Annahme, dass ein Satz immer in genau einen Satz übersetzt wird. Dadurch geht allerdings jegliche Information über die Bezugswörter (Antezessoren) von Pronomina verloren, und wenn zum Beispiel die Zielsprache mehrere (nach Geschlecht usw.) unterschiedliche Pronomina für ein Pronomen der Ausgangssprache hat, lässt sich diese Mehrdeutigkeit nicht auflösen.
Plie, la aŭtomata paraleligo de fonto- kaj cellingvaj frazoj en la korpusoj funkcias ja bone, sed ne perfekte. Homa paraleligo estas multekosta. Tial ekzistas diversaj aliroj apliki sintaksan aŭ leksikan informon por aŭtomata paraleligo.
Weiterhin funktioniert die automatische Parallelisierung von ausgangs- und zielsprachlichen Sätzen zwar gut, aber nicht perfekt. Parallelisierung durch Menschen ist teuer. Daher gibt es verschiedene Ansätze, zur automatischen Parallelisierung auch syntaktische oder lexikalische Information heranzuziehen.
En multaj tekstoj aperas elementoj, kiuj semantike apartenas al la sama malvasta kategorio, sed posedas multajn ekzemplojn, multe pli ol povas okazi en normala korpuso. De tiu speco estas individuaj nomoj de personoj, bestoj, lokoj, riveroj, landoj, kaj kvantaj esprimoj kiaj nombroj kaj datoj. Por ilin traduki necesas iu mekanismo de ĝeneraligo, kiu permesas traduki frazon kun la nombro "129" aŭ la nomo "Rabindranath Tagore" analoge al frazo kun "872" resp. "Umslopogaas".
In vielen Texten treten Elemente auf, die semantisch zur selben, sehr engen Kategorie gehören, aber sehr viele Ausprägungen besitzen, viel mehr als in einem normalen Korpus vorkommen können. Von dieser Art sind Eigennamen von Personen, Tieren, Orten, Flüssen, Ländern, und Mengenangaben wie Zahlen und Daten. Um sie zu übersetzen, ist ein Mechanismus zur Verallgemeinerung notwendig, der zum Beispiel erlaubt, einen Satz mit der Zahl "129" oder mit dem Namen "Rabindranath Tagore" analog zu einem Satz mit "872" bzw. "Umslopogaas" zu übersetzen.
Kelkaj aliroj kreas kategoriojn ankaŭ el semantike proksimaj vortoj (kvazaŭsinonimoj, ekz. interparoli kaj komuniki) kaj permesas la aplikon de ekzemplo, eĉ se necesas anstataŭigi vortojn per samkategoriaj aliaj vortoj.
Manche Ansätze fassen auch semantisch ähnliche Wörter (Quasisynomyme, wie sich unterhalten und kommunizieren) zu Kategorien zusammen und erlauben die Anwendung eines Beispiels, auch wenn es dazu nötig ist, manche Wörter durch andere aus derselben Kategorie zu ersetzen.